SECURITY (using OAuth 2.0)
Security is essential to any web application. In CE Hub, we have taken all possible measures to make the application secure. We are implementing spring security and OAuth 2.0 standards. Each request trying to communicate with the HUB must pass through the security layer of the application.

Fig 1. explains the communication between CE Hub and the different channels/devices.
There are three layers of security implemented:
- Authentication – The authentication is validating the user credentials. Only the users registered to the application can login providing their valid credential.
- Tenant verification – This layer verifies if the requesting user belongs to the tenant for which he/she is requesting the resources from. This restricts user from one customer/organization accessing other customers data.
- Authorization – Authorization means checking if the user is authorized to perform the requested task.
Fig 1. The flow of requests and response through the security of the application.
The figure is explained below.
Explanation:
- The HUB is protected by the security layer (The portion in green background), which means any communication into or out of the hub must pass through the security layer.
- At first the any requesting client must provide his/her authentication credentials to get inside the authentication layer.
- After authentication the OAuth will provide Refresh token and Access token which will be used to access the next layer of the security that is authorization layer. (More about OAuth 2.0 in the section 2 below).
- In the authorization layer a particular user will be provided a grant and some role which will decide what all activities he/she can perform in the HUB.
- After passing through the Authorization layer there is a Tenant verification layer, which will validate if the user belongs to the requested tenant or not. (More about multi tenancy explained in section 3 below.)
- OAuth 2.0
1.(a). Flow of OAuth 2.0 security

Fig. 2. OAuth 2.0 flow diagram for explaining the security flow.
Here is a more detailed explanation of the steps in the diagram:
- The application requests authorization to access service resources from the user
- If the user authorized the request, the application receives an authorization grant
- The application requests an access token & refresh token from the authorization server (API) by presenting authentication of its own identity, and the authorization grant
- If the application identity is authenticated and the authorization grant is valid, the authorization server (API) issues an access token & Refresh token to the application. Authorization is complete.
- The application requests the resource from the resource server (API) and presents the access token for authentication
- If the access token is valid, the resource server (API) serves the resource to the application
- If the access token expires after a certain period of time, we can re-issue the access token using the refresh token so that the username and password doesn’t need to be provided at each authentication process.
The actual flow of this process will differ depending on the authorization grant type in use, but this is the general idea. We will explore different grant types in a later section.
1.(b). User Details
The user details are stored in the database in the USER table which is related to ROLE and RIGHT in separate tables, so that a particular user can only perform activities which are permitted to his role and right only. The password is stored in BCrypt encryption format which uses a brute force method to encode the passwords, and most important is the bcrypt does not have any method which allows decoding the password, so nobody can ever decode the secure passwords.
1.(c). Application Registration
Before using OAuth with our application, we must register your application with the service. This is done through a registration form in the “developer” or “API” portion of the service’s website, where you will provide the following information (and probably details about your application):
- Application Name
- Application Website
- Redirect URI or Callback URL
The redirect URI is where the service will redirect the user after they authorize (or deny) your application, and therefore the part of your application that will handle authorization codes or access tokens.
1.(d). Client ID and Client Secret
Once your application is registered, the service will issue “client credentials” in the form of a client identifier and a client secret. The Client ID is a publicly exposed string that is used by the service API to identify the application, and is also used to build authorization URLs that are presented to users. The Client Secret is used to authenticate the identity of the application to the service API when the application requests to access a user’s account, and must be kept private between the application and the API.
1.(e). Authorization Grant
In the Abstract Protocol Flow above, the first four steps cover obtaining an authorization grant and access token. The authorization grant type depends on the method used by the application to request authorization, and the grant types supported by the API. OAuth 2 defines four grant types, each of which is useful in different cases:
- Authorization Code: used with server-side Applications
- Implicit: used with Mobile Apps or Web Applications (applications that run on the user’s device)
- Resource Owner Password Credentials: used with trusted Applications, such as those owned by the service itself
- Client Credentials: used with Applications API access
Now we will describe grant types in more detail, their use cases and flows, in the following sections.
1.(f). Grant Type: Authorization Code
The authorization code grant type is the most commonly used because it is optimized for server-side applications, where source code is not publicly exposed, and Client Secret confidentiality can be maintained. This is a redirection-based flow, which means that the application must be capable of interacting with the user-agent (i.e. the user’s web browser) and receiving API authorization codes that are routed through the user-agent.
1.(g). Example Access Token Usage
Once the application has an access token, it may use the token to access the user’s account via the API, limited to the scope of access, until the token expires or is revoked.
Here is an example of an API request, using curl. Note that it includes the access token:
curl -X POST -H “Authorization: Bearer ACCESS_TOKEN“”https://localhost:8080/ceapi/v2/$OBJECT”
Assuming the access token is valid, the API will process the request according to its API specifications. If the access token is expired or otherwise invalid, the API will return an “invalid_request” error.
1.(h). Refresh Token Flow
After an access token expires, using it to make a request from the API will result in an “Invalid Token Error”. At this point, if a refresh token was included when the original access token was issued, it can be used to request a fresh access token from the authorization server.
Here is an example POST request, using a refresh token to obtain a new access token:
https://localhost:8080/ceapi/oauth/token?grant_type=refresh_token&client_id=CLIENT_ID&client_secret=CLIENT_SECRET&refresh_token=REFRESH_TOKEN
1.(i). Token Store
We store all the tokens generated by the security process in the database so that even there is a system failure or un planned power shut-down the tokens generated will be available and they can be accessed after the system power gets restored.
Following are the six tables being used by the OAuth 2.0
- OAUTH_ACCESS_TOKEN
- OAUTH_APPROVALS
- OAUTH_CLIENT_DETAILS
- OAUTH_CLIENT_TOKEN
- OAUTH_CODE
- OAUTH_REFRESH_TOKEN
Some important tables are described below:
OAUTH_CLIENT_DETAILS contains the information related to access token and refresh token expiration time.
OAUTH_ACCESS_TOKEN stores all the access tokens.
OAUTH_REFRESH_TOKEN stores all the refresh tokens.
The tokens stored in the database are in encrypted format and are impossible to decode so even if someone gets access to database he/she can not get through the security of the application. The tokens are extrapolated to longblob format and uses bcrypt encryption policy.
2. Multi Tenancy

Fig. 3. Fine grained multi tenancy applied in the application to segregate tenant data from each other.
The above diagram explains that despite of having the same physical resource fo the tenant management we have separated the data of one tenant from another using the domain name and tenant id.
Every data in the database will be associated with a tenant id so that we can identify to which tenant the data belongs.

Fig. 4. Is the explanation of how one physical resource is separated from various tenants.
Fig. 4. This is how the virtual separation of single resource i.e. the HUB looks like.
As the HUB will be accessed by different clients we have also included the multi tenancy feature in the application. By including this a user from one tenant will not be provided grant to access other tenant’s resources.
In our context the tenant can be considered as a client or company,
Following is an example of the tenant feature:
Lets consider the following URL’s
https://www.company1.com/get-all-billofladings
https://www.company2.com/get-all-billofladings
In the above two example urls we can notice that we have company1 and company2 as the tenant identifiers.
We are using URL’s to identify tenants
In the above example the users of tenant1 will not be able to access the resources of tenant2 and viece versa. And if any user of tenant1 tries to access the resources of tenant2 he will be restricted to do so with 401 UnAuthorized response status and an error message.
To achieve this we are having a field called tenant in each table in the HUB which will separate the one tenant’s data from another.
By this architecture we can guarantee that we have the data related to one company secured from another company in database level.
Feedback/Comments are welcome
Thanks,
Kalyan






 Child project has the mail.jar dependency as well inherited from the parent even without mentioning the same in dependencies list in the child.
Child project has the mail.jar dependency as well inherited from the parent even without mentioning the same in dependencies list in the child.

 In this demo application we will see how to configure different database at runtime based on the specific environment by their respective profiles.
In this demo application we will see how to configure different database at runtime based on the specific environment by their respective profiles.




















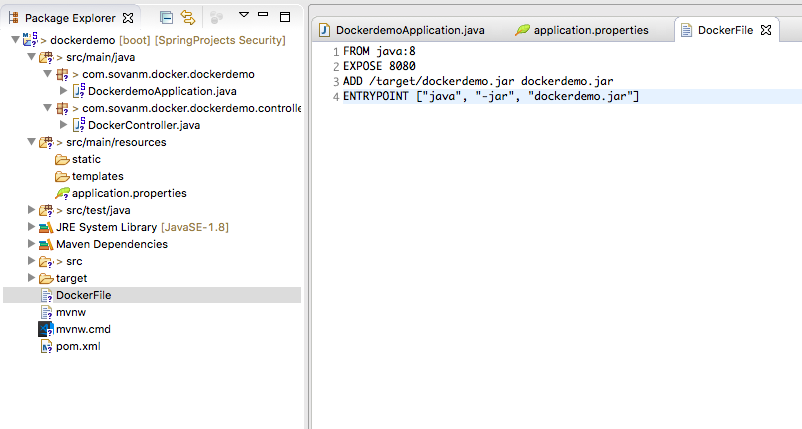
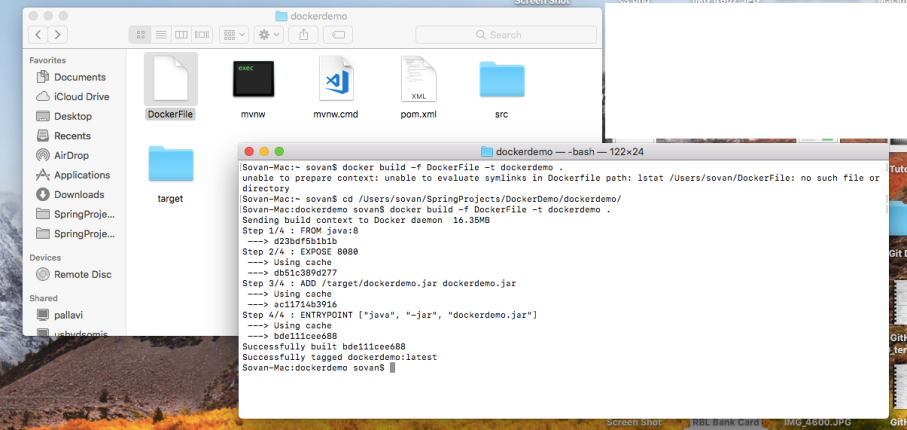

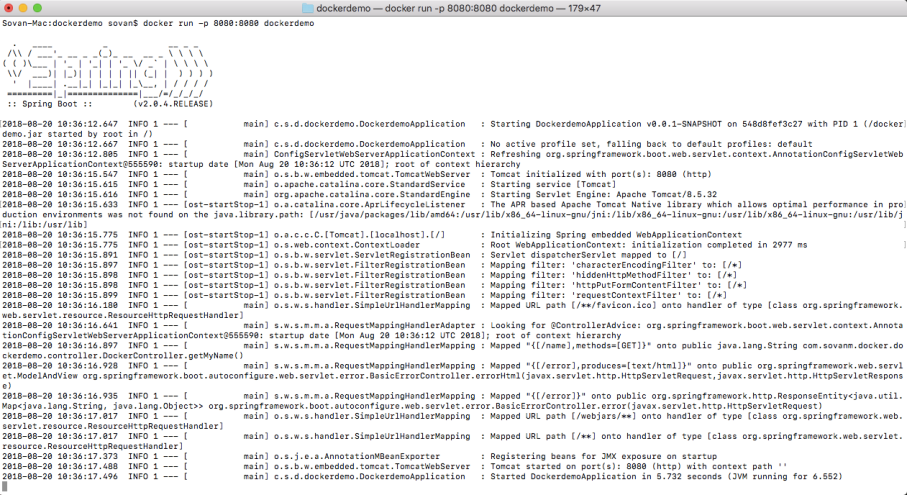 There you go.. Spring Boot Application Boots up.. and the server is running on the port (8080).
There you go.. Spring Boot Application Boots up.. and the server is running on the port (8080).
